Beyond Automation: Building Responsible and Defensible AI Data Extraction Workflows for HEOR
Introduction
AI-driven data extraction is transforming HEOR workflows, but this progress brings major challenges. When AI-generated data is inaccurate or unvalidated, a single error, such as an incorrect prevalence estimate, can undermine entire epidemiological models, skew economic analyses, and ultimately lead to poor healthcare decisions.
Many in the HEOR community now face a pressing dilemma: How do we realize AI’s efficiency and speed while maintaining the trust, regulatory compliance, and patient safety required for high-stakes evidence generation?
The solution isn’t unchecked automation; it’s building responsible, transparent, and defensible AI workflows.
This article presents practical strategies, aligned with ISPOR and NICE guidelines and integrated lessons learned from experiences, to help HEOR professionals harness AI’s benefits while safeguarding the integrity of their evidence.
Why AI-Assisted Data Extraction Matters in HEOR
Data extraction is the most time- and resource-intensive part of systematic and targeted literature reviews, often taking weeks or months. In HEOR, especially for rare diseases, reviews may involve pulling study design, patient demographics, treatments, and outcomes from dozens of papers to construct economic or epidemiological models. This complexity makes efficiency critical.
AI automation can reduce evidence synthesis time by 30–80% and improve accuracy, particularly for RCTs, which are prone to errors.
Nevertheless, speed should not compromise reliability, transparency, or trust. A clear understanding of AI’s strengths and limitations in HEOR data extraction is essential for credible healthcare decisions.
Where AI Can Succeed and Struggle
NICE highlights data extraction as one of AI’s greatest challenges in HEOR. Understanding where AI performs well and where it does not lets us maximize benefits while managing risks.
Scientific studies show AI can extract data from randomized controlled trials (RCTs) with 96–97% accuracy and process documents 80% faster than manual extraction. However, issues persist: AI may fabricate data (hallucinations) or produce inconsistent results for the same task.
The following summarizes AI’s strengths and weaknesses in data extraction, based on both published use cases and my experience with rare disease and non-RCT sources.
Where AI performs well
- Zero-shot learning
- Handling diverse formats
- Generalizability
- Standardization
Where human validation is essential
- Complex study design
- Ambiguous data and inferences
- Cohort and arm recognition
- Context-dependent interpretation
The table below summarizes data area-specific AI performance based on my experience of data extraction across 600+ literature sources spanning four rare diseases.
Table 1. Concrete examples of AI performance in extracting epidemiology and health economy data
| Data areas | Example | AI performance |
|---|---|---|
| Epidemiology and demographics | Study metadata, study design, population characteristics | AI performs well |
| Clinical manifestations | Symptom frequency, symptom timing | Human validation is necessary |
| Relapse characteristics | Relapse clinical frequency, relapse timing, and relapse tracking method | Human validation is necessary |
| Longitudinal clinical outcomes | Functional outcomes, recovery metrics, disease severity outcomes | Human validation is necessary |
| Disease course and trajectory | Clinical stabilization, longitudinal assessements | Human validation is necessary |
| Healthcare resouce utilization | Hospital utilizatoin, ICU utilizatoion, hospital length of stay | AI performs well |
Why Transparency and Defensibility Matter
In HEOR, transparency and defensibility of AI-generated evidence are critical because they influence major healthcare decisions.
Defensibility means being able to justify and explain findings and methods, especially when questioned by regulators.
Defensibility in AI-assisted evidence generation relies on several core elements:
- Clear justification: Evidence should be transparent, reliable, and auditable to withstand challenges.
- Accountability: Organizations must stand behind all content, including AI-generated content, with human oversight to ensure rigor.
- Scientific integrity: Research must be reproducible and open to audit, with clear documentation of the use of AI tools.
- Prioritize accuracy and transparency; AI is only defensible if it does not increase the risk of error.
- Validation: AI tools must be tested to ensure consistent, reliable results, even in unusual cases.
- Traceability: Openness about data, code, and methods makes findings more understandable and defensible.
Defensibility ensures AI-generated evidence not only supports human expertise but also maintains stakeholder trust in crucial healthcare decisions.
Why is defensibility significant?
- It directly impacts patient outcomes and major decisions.
- It preserves scientific integrity and reproducibility.
- It builds trust with stakeholders and regulators.
- It’s essential for legal and regulatory compliance.
- It reduces risks and biases in AI-generated evidence.
Emerging Guidance and Standards
There is not yet much authoritative regulatory guidance, and standards are emerging for AI or LLMs in data extraction for evidence synthesis, especially in HEOR.
When searching with AI tools, three specific publications are highlighted: HEOR-specific guidance, evidence synthesis standards, and HTA practice.
ELEVATE-GenAI framework and checklist (HEOR-specific guidance, ISPOR 2025)
This document, introduced above, is highly relevant to HEOR and is designed specifically for LLM-assisted HEOR studies. It introduces a framework for evaluating reporting based on several domains, including transparency, accuracy, reproducibility, and fairness/bias.
It provides a practical checklist for the audience who need to report on how an LLM was used for tasks such as systematic literature review, data extraction, model selection, prompting, validation, and error handling.
RAISE 1, 2, and 3 (Evidence-synthesis standards, NICE 2026)
The RAISE framework family for evidence synthesis workflows offers guidance as follows: RAISE 1 addresses roles and responsibilities; RAISE 2 provides guidance on building and evaluating AI tools; and RAISE 3 focuses on selecting and using these tools in specific syntheses.
Specifically for data extraction, RAISE 2 addresses validation, performance metrics, evaluation design, and the reporting of AI evidence synthesis tools, while RAISE 3 guides the selection of appropriate models for a given revision, dataset, or extraction task.
NICE’s position statement (HTA practice, NICE 2024)
NICE’s position statement on AI in evidence generation and reporting serves as a practical HTA-facing standard. It states that AI should be used to augment, not replace, human involvement.
NICE also emphasizes transparency, rigor, trust, and the use of existing regulations and best-practice guidance where appropriate, which makes it highly relevant to HTA/HEOR teams adopting LLMs for extraction.
Table 2. Summary of NICE and ISPOR documents
| Standard | Author | Main Contribution |
|---|---|---|
| ELEVATE-GenAI | ISPOR | Reporting |
| RAISE2 | NICE | Development and validation |
| NICE’s position statement | NICE | Governance and oversight |
Lifecycle for Defensible AI Data Extraction
RAISE 2 recommends a lifecycle following a structured path from scoping to post-launch auditing.
Below is an outline of the five-phase lifecycle, along with a brief summary of key technical details from the RAISE 2 document. I have omitted steps related to training the model on the train and test datasets and slightly tailored the workflow for data extraction.
Understanding necessary computational concepts (e.g., recall, precision, edge cases, and hallucinations) and general principles for developing automated tools is important for improving awareness of the responsible use of AI in the literature review process, including data extraction.
Continuing from this foundation, RAISE 2 states that developing an AI prompt is like building a machine learning model. Non-developers creating prompts may need to understand the RAISE 2 lifecycle to meet HTA guidelines.
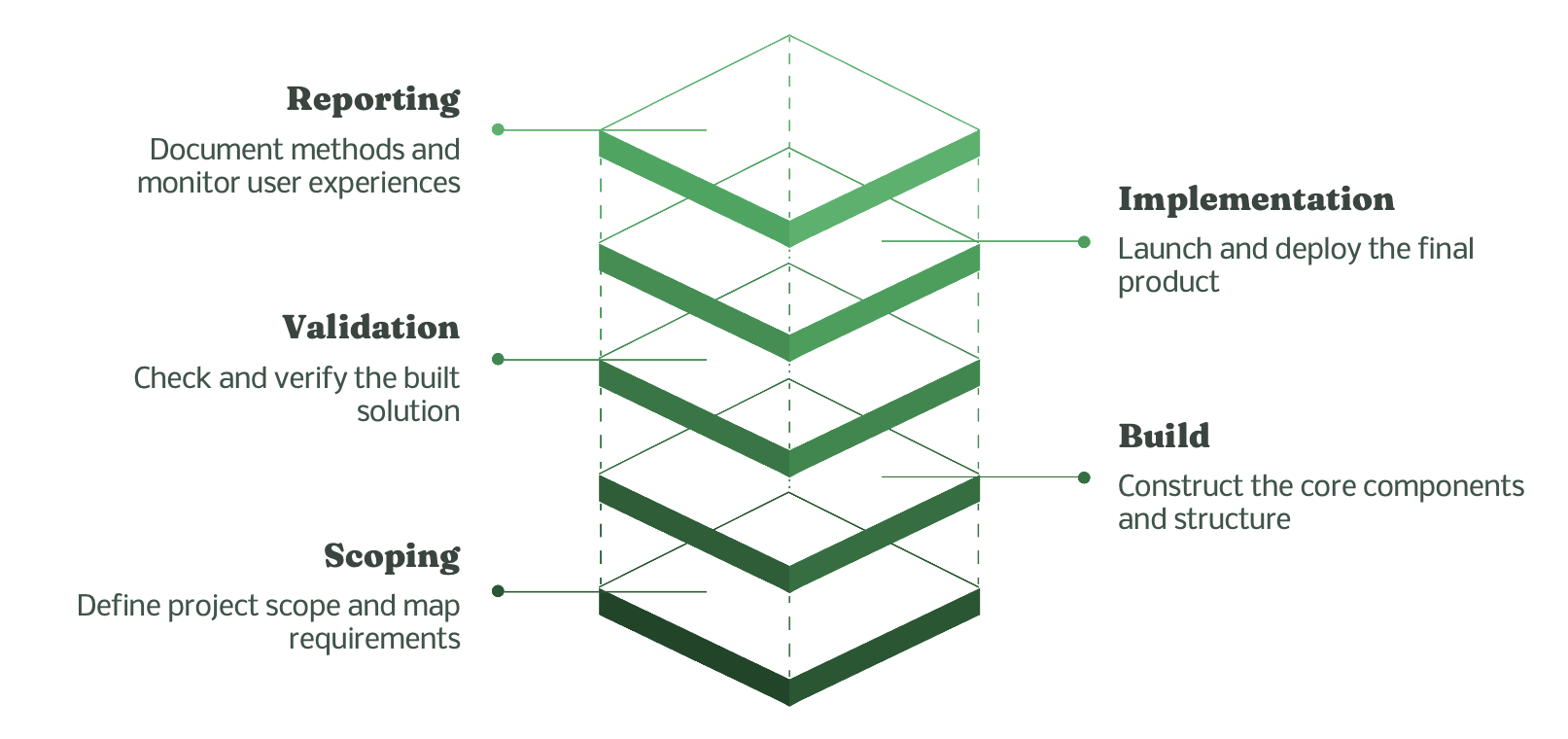
Phase 1: Scoping and stakeholder engagement
- Engage stakeholders: Engage a diverse group, including methodologists and evidence synthesists, to ensure the tool aligns with community values.
- Define Standards: Establish the required level of accuracy, such as recall (the proportion of relevant items the tool retrieves) versus precision (the proportion of retrieved items that are actually relevant), before use.
- Implement accountability: Use responsible innovation frameworks and ethics advisory boards to guide development.
Phase 2: The build phase
- Refine prompts iteratively: For generative AI, select a small training dataset and iteratively refine prompts to achieve the desired extraction results.
- Control variability: Set parameters to minimize non-deterministic variation and ensure consistency across multiple runs.
- Document process: Record prompt evolution and whether prompts were generated manually or automatically to ensure replicability.
Phase 3: The validation phase
- Assess stability: Run identical inputs multiple times and record output variations to estimate the frequency and severity of deviations.
- TTest robustness: Test edge cases and assess the system’s response to unexpected or nonsensical inputs.
- Check for hallucinations: Manually confirm that extracted data are based on the input document rather than invented or hallucinated information.
Phase 4: Implementation and human oversight
- Human-in-the-loop: Set up the system so humans maintain control over operations and outputs.
- Verify data prior to prompting: Confirm the information exists in the source document before prompting the AI to extract it.
- Manual severity checks: Human reviewers must manually compare AI output with gold standards to determine the type and severity of errors.
Phase 5: Reporting and auditing
- Report transparently: Publicly and honestly document building and evaluation methods, including data sources, prompt development details, and any identified biases.
- Conduct post-launch auditing: Continuously audit the algorithm and outputs to monitor user experiences and assess social impacts.
Practical Lessons
Guided by NICE and ISPOR guidelines and standards, I reflect on my experience with AI-assisted data extraction to generate evidence for rare diseases.
Initially, my efforts were experimental, but over time, I shifted toward intentional development aligned with authority standards, even though they were not mandatory at the time.
Informed by both guidelines and my evolving experience, I undertook data extraction from 600+ literature sources spanning four rare diseases, which shaped my key lessons.
- Lesson 1: Developing a prompt library that is reusable across diseases is both feasible and efficient, as prompts perform well across different conditions.
- Lesson 2: AI data extraction varies in accuracy and consistency across data elements.
- Lesson 3: When thorough documentation is maintained, responsible use and internal development are supported. Collaboration and review benefit from tracking models, prompt changes, and noting edge cases.
- Lesson 4: To build a robust quality assurance workflow, monitor for false positives and false negatives. Confirm that programs operate stably on consistent inputs.
- Lesson 5: Ensure human oversight is integrated at critical points in both operation and quality-assurance workflows.
- Lesson 6: Recording references with granular table-, figure-, and section-level precision facilitates cross-validation by multiple reviewers.
Future Directions
According to research presented at the 2025 ISPOR conferences, future directions for AI in literature reviews focus on improving technical capabilities, developing regulatory guidance, and expanding into specialized areas.
Key future trajectories include:
Technical optimization
Researchers and developers advance AI-assisted table extraction methods, assess study quality, and work to reduce false negatives while enhancing the sensitivity and specificity of screening tools.
Standardized guidelines and frameworks
Stakeholders and HTA agencies continuously collaborate to develop standardized frameworks that ensure the reliability and reproducibility of AI tools and to establish industry standards.
Specialized applications
Researchers move toward specialized applications. For example, they use rapid AI reviews to support orphan drug applications that require specific prevalence evidence. They also accelerate systematic reviews and meta-analyses in epidemiology with AI.
Human-AI partnership
AI complements, rather than replaces, human expertise. Experts oversee interpretation, control data, and ensure regulatory compliance while AI plays a supportive role.
Reference
- Gartlehner, G., et al. (2024). Data extraction for evidence synthesis using a large language model: A proof-of-concept study. Research synthesis methods, 15(4), 576–589. https://doi.org/10.1002/jrsm.1710
- Gartlehner, G., et al. (2025). From promise to practice: challenges and pitfalls in the evaluation of large language models for data extraction in evidence synthesis. BMJ evidence-based medicine, 30(6), 385–389. https://doi.org/10.1136/bmjebm-2024-113199
- Lee, K., et al. (2024). SEETrials: Leveraging large language models for safety and efficacy extraction in oncology clinical trials. Informatics in medicine unlocked, 50, 101589. https://doi.org/10.1016/j.imu.2024.101589
- Fleurence, R. L., et al. (2025). ELEVATE-GenAI: Reporting Guidelines for the Use of Large Language Models in Health Economics and Outcomes Research: An ISPOR Working Group Report. Value in health : the journal of the International Society for Pharmacoeconomics and Outcomes Research, 28(11), 1611–1625. https://doi.org/10.1016/j.jval.2025.06.018
- Responsible use of AI in evidence SynthEsis (RAISE): recommendations and guidance. Open Science Framework.